File Processing#
The file processing library is a metadata extraction tool that supports 26 common file types, including OCR for image files and transcription for audio/video files. There are 3 main use cases:
- Extracting metadata from individual files
- Extracting metadata from files in a directory and generating reports (.csv) that:
- list metadata for each file
- provide aggregate statistics on file size and count of each file type
- compare file similarity of document-based files to identify possible duplicates in a directory
- Comparing 2 document-based files via cosine similarity and Levenshtein distance
Example Usage and Output#
Test files can be found in docs/sample_reports and examples are shown below
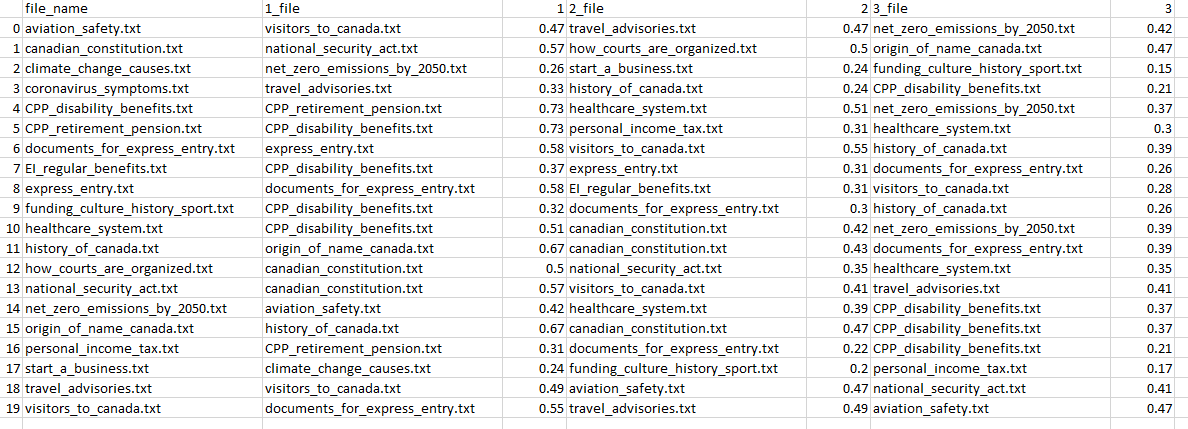
Lists metadata of all files. There are multiple report configurations and only a subset of the columns are shown:
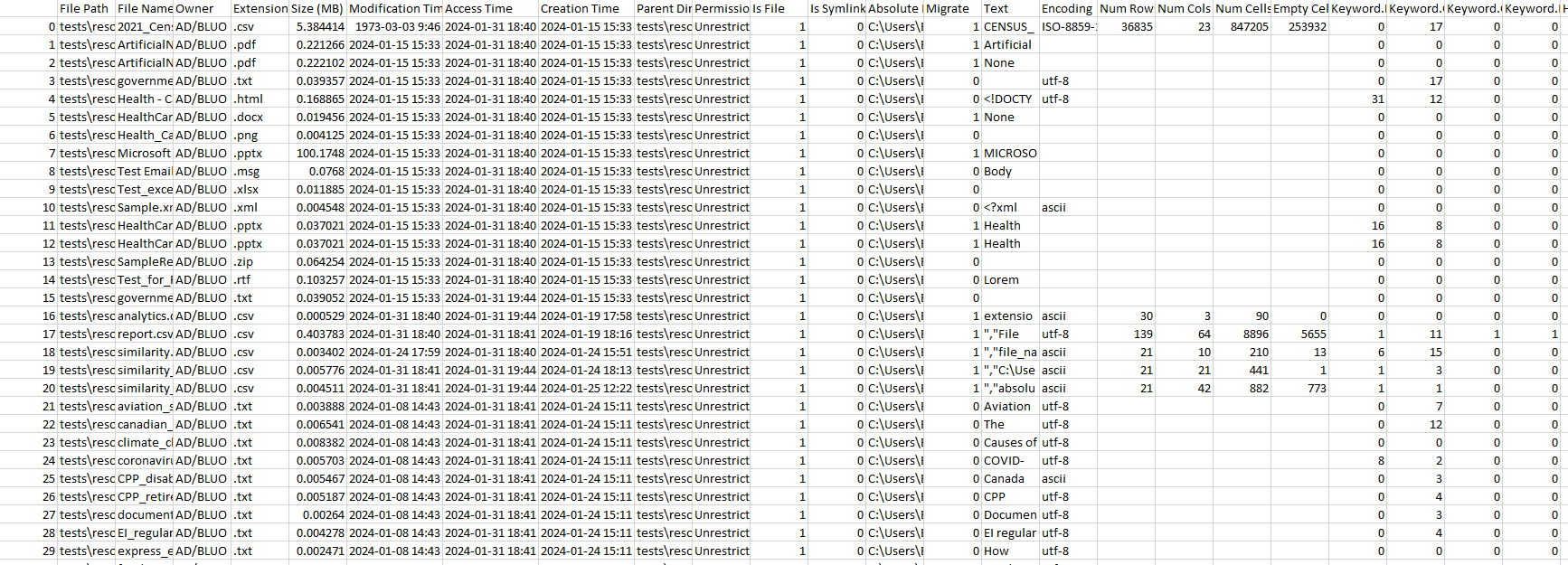
Aggregates file size and count for each file type.
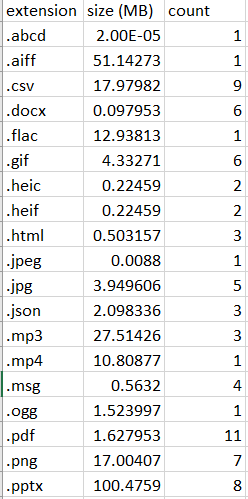
Compares the text in each document-based file to every other file according to cosine similarity.
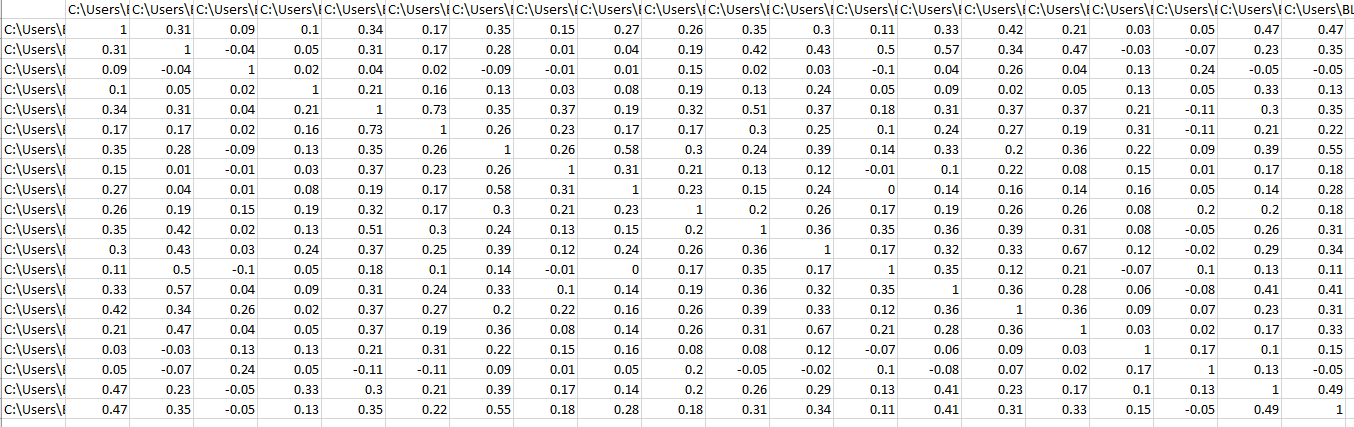
Determines the top n matches to each file using FAISS indicies.
from file_processing import File
file = File('path/to/file')
print(file.metadata)
{
'original_format': 'PNG',
'mode': 'RGBA',
'width': 1188,
'height': 429
}
Supported File Types and Extracted Metadata#
File Type |
Metadata Fields |
Example |
|---|---|---|
[All file types] |
|
|
mp3, wav, mp4, flac, aiff, ogg |
|
|
jpeg, png, heic/heif, tiff/tif |
|
|
gif |
|
|
csv |
|
|
xlsx |
|
|
docx |
|
|
pptx |
|
|
html, txt, xml |
|
|
json |
|
|
msg |
|
|
|
|
|
py |
|
|
rtf |
|
|
zip |
|
|